파이썬 pandas 기초 정리 많이 쓰이는 기능.2
본 포스팅은 https://www.learndatasci.com/tutorials/python-pandas-tutorial-complete-introduction-for-beginners/ 를 참고하여 한국말로 재정리 한 포스트 입니다.
이전 포스트
가장 중요한 DataFrame 기능
DataFrame에는 데이터를 분석하기위한 여러가지의 메쏘드와 기능들이 있습니다. 입문자로써 데이터를 분석하기위해 변형시키고 조작해야 할 필수적인 메쏘드를 알아보겠습니다.
이번 튜토리얼에 필요한 데이터는 아래의 경로에 있습니다.
github.com/LearnDataSci/articles/tree/master/Python%20Pandas%20Tutorial%20A%20Complete%20Introduction%20for%20Beginners
IMDB 영화 목록이 담긴 데이터를 로드해보겠습니다.
movies_df = pd.read_csv("IMDB-Movie-Data.csv", index_col="Title")
여기서 우리는 movie title을 인덱스로 지정하는 CSV를 로드하였습니다.
데이터 확인하기
데이터셋을 열어볼때 해볼 수 있는것은 시각적으로 확인할 수 있는 몇개의 row 들을 확인해 보는 것입니다. 이때 .head()를 이용할 수 있습니다.
movies_df.head()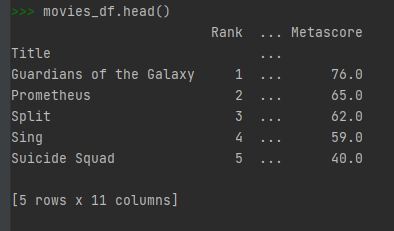
.head()는 첫번부터 다섯번째까지의 row들을 아웃풋해줍니다. 만약 movies_df.head(10) 과같이 숫자를 인자값으로 넣어주면 위에서 10번째까지의 row들을 출력시켜줍니다.
만약 마지막번째로부터 5개의 row들을 보고 싶다면 .tail() 을 사용할 수있습니다.
movies_df.tail(2)
데이터의 정보 확인하기
.info() 는 로딩한 데이터의 정보를 알아 낼 수 있습니다.
movies_df.info()
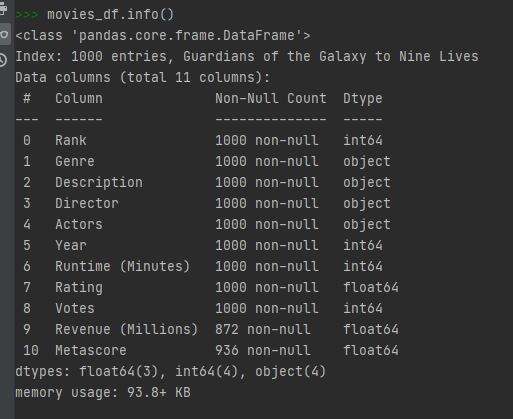
.info() 는 디테일하게 데이터에 대한 정보를 알려줍니다. row나 column의 갯수나 non-null 의 갯수, 각각의 column의 데이터 타입 그리고 DataFrame의 용량정보까지 알 수있습니다.
위의 데이터를 통해 Revenue와 Metascore column에 몇 몇의 값들이 빠져있는것을 확인할 수 있습니다. 앞으로 이러한 데이터를 어떻게 수정할 것인지 차차 알아보겠습니다.
또다른 정보를 알아볼 수 있는 간단한 방법은 아래와 같습니다.
movies_df.shape

.shape은 소괄호없는 간단한 튜플형(rows, columns)입니다. 즉 1000개의 row와 11개의 column이 movies DataFrames에 존재하는 것입니다.
중복된 데이터 처리하기
현재의 데이터는 중복된 row 데이터는 없습니다. 하지만 중복된 데이터를 확인하는 방법은 다음과 같습니다.
먼저 현재의 DataFrame을 두배로 뻥튀기한 후 템프 변수에 저장합니다.
temp_df = movies_df.append(movies_df)
temp_df.shape
append()를 이용하면 원본 DataFrame은 그대로 두고 temp 변수에 저장하는 것이기에 안전하게 처리할 수 있습니다.
여기서 .shape 을 이용하여 DataFrame의 row갯수가 두배가 된 것을 확인할 수 있습니다.
이제 중복된 것을 드랍시켜보겠습니다.
temp_df = temp_df.drop_duplicates()
temp_df.shape
여기서 같은 변수에 재저장하는 것이 어떻게 보면 약간 지저분해 보일 수도 있겠습니다. 그래서 판다스는 inplace라는 인자가 존재하는데 inplace=True 는 메쏘드 자체에서 데이터를 변형시켜 저장을 시켜줍니다.
temp_df.drop_duplicates(inplace=True)
이제 temp_df 에 자동으로 변형된 데이터가 저장되었습니다.
또다른 중요한 인자로는 keep 이라는게 있습니다. 여기에는 3가지 옵션이 있는데
- first: (기본값) 중복된 것들중 첫번재를 제외한 나머지를 지웁니다.
- last: 중복된 것들중 마지막을 제외한 나머지를 지웁니다.
- False: 중복된 모든것을 지웁니다.
이전 예제에서 keep 인자를 사용하지 않았으므로 기본값이 first 가 적용되었습니다. 다시 말해 두개의 똑같은 row가 발견되었을 때 판다스는 두번째 row를 지우고 첫번째 row는 남겨둔다는 뜻입니다. last 값은 이와 반대로 적용되게 됩니다.
Column 정리하기
데이터에는 때때로 symbol, 대문자 또는 소문자 그리고 빈칸 등등이 들어갈 수도있습니다. 이렇게 column 이름값을 선택하기 위해 재정리가 필요합니다.
column만 데이터를 추출하기 위해서 아래와 같이 입력합니다.
movies_df.columns
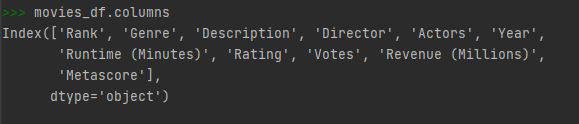
자, 이제 여기서 모든 이름들을 소문자화 시켜보겠습니다. .rename() 함수를 이용하는 것 대신 다음과 같이 직접 입력할 수도 있습니다.
movies_df.columns = ['rank', 'genre', 'description', 'director', 'actors', 'year', 'runtime',
'rating', 'votes', 'revenue_millions', 'metascore']
print(movies_df.columns)
하지만 이렇게 입력하기엔 너무 귀찮지요, 그렇다면 각각의 column들을 list comprenhension을 이용해서 다음과같이 할 수 있습니다.
movies_df.columns = [col.lower() for col in movies_df]
판다스에서 list(dict) comprehension을 이용하면 손쉽게 작업이 가능합니다.
빠져있는 값들 처리하기
데이터를 처리하다보면 빠져있거나 null 값들이 많이 보일 수도 있습니다. null 값을 지우는 방법은 다음과 같습니다.
movies_df.dropna()
.dropna() operation은 어떠한 row든지 적어도 하나의 null값이 있다면 지우게 됩니다. 이 operation도 마찬가지로 재저장이 안되기에 inplace=True 인자를 써야합니다.
이상황에서는 128 개의 revenue_millions의 null값 그리고 64개의 metascore row들을 지우게 됩니다. 하지만 이렇게 데이터를 지웠을 때 중요한 데이터의 손실을 가져올 수 있습니다. 즉, null값이 아닌 데이터들이 없어지기 때문이죠.
모든 row 값들을 지우는 대신 axis=1 을 이용해서 columns를 지울 수도 있습니다.
movies_df.dropna(axis=1)이렇게 되면 revenue_millions 와 metascore columns가 없어지게 됩니다.
여기서 axis=1 의 의미?
axis 라는 인자값으로 1이라는 뜻은 먼저 이전에 보았던 .shape 값을 보면 알 수가 있습니다.
movies_df.shape
Out: (1000, 11)
앞서 배웠듯이, DataFrame 의 shape을 표현해주는 tuple형 값입니다. 1000 행과 11 열을 나타내고 있습니다.
즉, index 가 0은 row를 뜻하면 1은 column을 뜻하게 됩니다. 이러한 이유로 index=1이라는 것은 column을 나타내며 이것의 방식은 기본적으로 NumPy에서 가지고왔습니다.
Imputation
Imputation은 null값을 그대로 유지하면서 데이터 손실을 없게 해주는 방법입니다.
다시말하면, null값을 평균치값이나 중간값으로 넣어주는 것입니다.
null값이 있었던 revenue_millions의 columns 을 이용해보겠습니다. 먼저 column을 하나의 값으로 추출합니다.
revenue = movies_df['revenue_millions']DataFrame에서는 파이썬의 dict 형처럼 대괄호를 이용해 column값을 직접적으로 추출할 수 있습니다. 이제 revenue는 Series 형의 데이터를 가지고 있습니다.
revenue.head()
이전에 보았던 DataFrame 형식과는 다르지만 title의 index는 여전히 존재합니다.
먼저 평균치를 구하겠습니다.
revenue_mean = revenue.mean()
print(revenue_mean)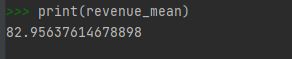
이제 fillna() 메소드를 이용해 null값을 채워보겠습니다.
revenue.fillna(revenue_mean, inplace=True)이제 revenue에 null값들이 채워졌으며 여기서 inplace=True를 사용했기에 원본 데이터 movies_df에 영향이 미치게 됩니다.
movies_df.isnull().sum()
값들을 이해하기
describe() 을 이용해서 전체 DataFrame의 연속변수(continous variable) 통해 summary를 알 수가 있습니다.
movies_df.describe()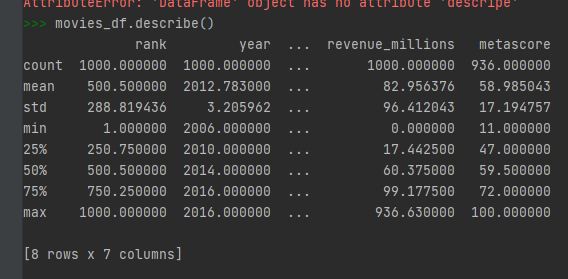
.descripe() 는 row의 데이터들만 취합해 category의 갯수, top category, top category의 갯수 등을 알수 있습니다.
movies_df['genre'].describe()
이것은 207개의 유니크한 장르값이 있으며, 그중 가장 많은 장르는 Action/Adventure/Sci-Fi 이며 총 50가 있습니다.
value_counts() 는 column에서 몇개의 값이 쓰였는지를 보여줍니다.
movies_df['genre'].value_counts().head(10)
연속 변수들의 상관관계
.corr() 을 이용해서 각각의 연속변수들의 상관관계를 알 수가 있습니다.
movies_df.corr()
상관관계표(Correlation table)은 단순상관관계(bivariate relationships)을 숫자적으로 나타내는 표입니다.
양수 값은 상관관계가 있다는 것을 표시합니다. 즉, 하나의 값이 올라갈 때 다른 값이 올라간다는 것이죠.
음수 값은 반대의 의미로 하나의 값이 올라갈 때 다른 값은 내려가는 것입니다. 1은 완벽하게 두개의 값이 일치하는 것을 나타냅니다.
위의 출력에서 알 수 있듯이 첫번째 row와 column은 1로 완벽하게 일치 하는 것입니다. 이와는 반대로 votes와 revenue_millions는 0.6 으로 약간은 비슷한걸 알 수가 있겠습니다.
DataFrame Copy 하기
DataFrame 을 이것저것 조합하고 또다른 변수로 넣었다가 수정하다보면 다음과 같은에러가 뜰때가 있습니다.

SettingWithCopyWarinig 은 기존 다른변수로 넣기전의 DataFrame 의 데이터가 수정될 때 나타나는 에러입니다.
다시말하면 판다스의 DataFrame은 메모리할당으로 인한 부족문제때문에 기존 DataFrame을 또다른 변수로 할당한다고 할지라도 카피돼서 할당되는게 아닌 그 이전 데이터를 가르키는 형식으로 저장이됩니다.
따라서 새로 할당된 변수에서 기존 data의 수정이 일어날경우 불가피하게 일어나는 에러인 경우입니다.
이러한 문제를 해결하려면 다음과같이 다른 변수로 할당하기전 .copy() 메쏘드를 이용하여 독립된 카피데이터를 생성시켜 할당해주면 됩니다.
'프로그래밍 > python' 카테고리의 다른 글
| 파이썬 datetime 모듈로 날짜 관련형식 정복하기 (0) | 2020.12.25 |
|---|---|
| 파이썬 pandas 기초 정리 DataFrame 수정하기..3 (0) | 2020.12.25 |
| 파이썬 pandas 기초 정리 데이터 읽고 쓰기..1 (0) | 2020.12.25 |
| 파이썬 패키지 __init__.py 를 이용해서 만드는 법 (2) | 2020.12.23 |
| 스크래피 scrapy 이거 하나로 익숙해지기..2 (2) | 2020.12.21 |


