본 포스트는 외국 사이트의 내용을 한국어로 재정리한 글입니다.
이번 포스트에서 다룰 내용은 아래와 같습니다.
-
pandas의 groupby를 진짜 세계데이터에서 사용하는 법
-
단계별로 split-apply-combine 하는법
-
다시 split-apply-combine 을 decompose 하는법
-
pandas groupby를 이용해서 속해있는 데이터에따라 다른 카데고리에 위치시키는 방법
들어가기에 앞서서
# 소수 셋째자리 밑으로는 과학적 표기법으로 표시 설정
pd.set_option("display.precision", 3)
# 데이터를 표시해주는 프레임 라인 안보이게 설정
pd.set_option("display.expand_frame_repr", False)
# row의 표시를 25줄로 설정
pd.set_option("display.max_rows", 25)다음과 같이 pandas의 데이터 표시 설정을 해줍니다.
이 링크에서 현실세계에 쓰이는 data set을 다운 받습니다.
예제 1: U.S 의회 dataset
미국 의회 리스트 데이터를 이용할 것입니다. 먼저 CSV파일을 read_csv() 함수로 데이터를 read합니다.
import pandas as pd
dtypes = {
"first_name": "category",
"gender": "category",
"type": "category",
"state": "category",
"party": "category",
}
df = pd.read_csv(
"groupby-data/legislators-historical.csv",
dtype=dtypes,
usecols=list(dtypes) + ["birthday", "last_name"],
parse_dates=["birthday"]
)이 dataset에는 성과 이름, 생일, 성별, 타입(rep='하원', sen='상원'),U.S 주, 당 등의 데이터가 있으며 df.tail()을 이용해서
마지막 데이터의 정보를 볼 수 있습니다.
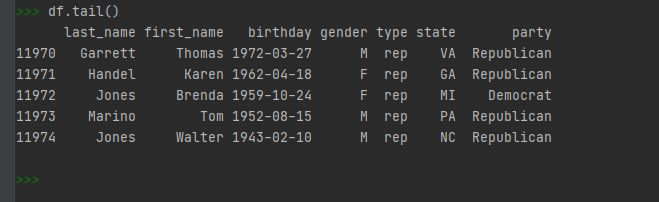
여기서 이 DataFarme은 메모리 효율을 높이기 위해 categorical dtypes을 사용합니다.

dtypes를 통해 대부분의 데이터 타입이 category인걸 알 수가 있는데 이는 메모리량을 줄여주는 역할을 합니다.
이제 groupby가 무엇인지 알아볼까요
자, 만약 SQL에서 위의 data set을 이용해서 각 주마다 의회의 멤버 리스트를 뽑는다면 아래와 같은 SELECT statement를 사용하는걸 볼 수 있습니다.

이제 파이썬에서 비슷하게 실행하는 방법입니다.
>>> n_by_state = df.groupby("state")["last_name"].count()
>>> n_by_state.head(10)
groupby()의 인자값에 그룹핑할 column 이름을 넣고 ["last_name"] 을 이용해 특정 column만 불러오게 합니다.
.groupby()에는 첫번째 이자값에 하나의 column 뿐만아니라 다음과 같은 여러타입을 지정 할 수 있습니다.
- 여러 column 의 리스트
- Series 나 dict
- Numpy array 나 Pandas 의 Index, iterable 가능한 array
그 다음으로 두개의 column을 이용해 그룹핑한 예제입니다.
>>> df.groupby(["state", "gender"])["last_name"].count()
예제 2: 공기 질 dataset
이 data set은 한시간별로 이태리에서 공기를 측정한 것으로, 측정 안되는 빠지는 값은 -200으로 CSV파일을 불러올 때 명시를 하였습니다. 또한 read_csv() 함수에서 두개의 column을 하나의 timestamp 으로 만들어 인덱스로 사용하였습니다.
import pandas as pd
df = pd.read_csv(
"groupby-data/airqual.csv",
parse_dates=[["Date", "Time"]],
na_values=[-200],
usecols=["Date", "Time", "CO(GT)", "T", "RH", "AH"]
).rename(
columns={
"CO(GT)": "co",
"Date_Time": "tstamp",
"T": "temp_c",
"RH": "rel_hum",
"AH": "abs_hum",
}
).set_index("tstamp")이 코드는 Datetime Index와 4개의 float column의 DataFrame을 만듭니다.

여기서 co 는 한시간동안의 평균 일산화탄소, 이고 temp_c는 섭씨 온도, rel_hum(relative_humidity)는 상대습도, abs_hum(absolute humidity)는 절대습도 를 나타냅니다. 측정은 2004 march에서 2005 april 까지 되어있습니다.

Array를 이용해서 그룹핑하기
이전에 .groupby()는 여러타입의 인자값을 넣을 수 있다고 알려드린적 있습니다.
-
여러 column 의 리스트
-
Series 나 dict
-
Numpy array 나 Pandas 의 Index, iterable 가능한 array
만약 일주일별로 하루씩 그룹을 한다고 했을 때 마지막 3번째 옵션을 이용하면 가능합니다. 먼저 판다스의 index중 .day_name()을 이용해서 어떻게 하는지 알아보겠습니다.
>>> day_names = df.index.day_name()
>>> type(day_names)
<class 'pandas.core.indexes.base.Index'>
>>> day_names[:10]
Index(['Wednesday', 'Wednesday', 'Wednesday', 'Wednesday', 'Wednesday',
'Wednesday', 'Thursday', 'Thursday', 'Thursday', 'Thursday'],
dtype='object', name='tstamp')여기서 day_names 는 array입니다. 1차원의 시쿼스형 입니다.
>>> df.groupby(day_names)["co"].mean()

여기서 만약 하루가 아닌 한시간별로 알고 싶다면 어떻게 해야할까요? 결과는 7 * 24 = 168 개의 정보가 나올 것입니다.이렇게 하기 위해서는 판다스의 인덱스 오브젝트(Int64Index)를 사용하면 됩니다.
>>> hr = df.index.hour
>>> df.groupby([day_names, hr])["co"].mean().rename_axis(["dow", "hr"])
dow hr
Friday 0 1.936
1 1.609
2 1.172
3 0.887
4 0.823
...
Wednesday 19 4.147
20 3.845
21 2.898
22 2.102
23 1.938
Name: co, Length: 168, dtype: float64